Prerequisites
This guide assumes that you are using Windows 10 and the user had admin permissions.
System requirements:
- Windows 10 OS
- At least 4 GB RAM
- Free space of at least 20 GB
Installation Procedure
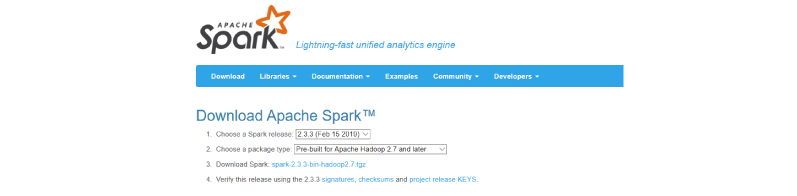
Step 1: Go to the below official download page of Apache Spark and choose the latest release. For the package type, choose ‘Pre-built for Apache Hadoop’.
The page will look like below.
Step 2: Once the download is completed unzip the file, to unzip the file using WinZip or WinRAR or 7-ZIP.
Step 3: Create a folder called Spark under your user Directory like below and copy paste the content from the unzipped file.
C:\Users\<USER>\Spark
It looks like below after copy-pasting into the Spark directory.

Step 4: Go to the conf folder and open log file called, log4j.properties. template. Change INFO to WARN (It can be ERROR to reduce the log). This and next steps are optional.
Remove. template so that Spark can read the file.
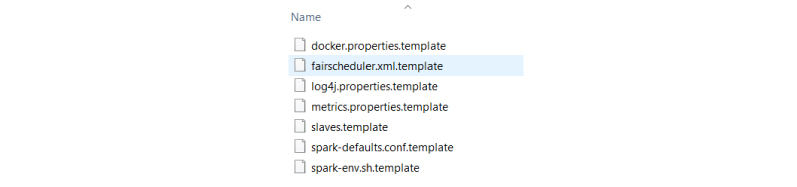
Before removing. template all files look like below.
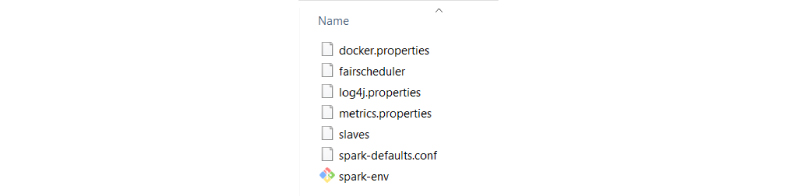
After removing. template extension, files will look like below
Step 5: Now we need to configure path.
Go to Control Panel -> System and Security -> System -> Advanced Settings -> Environment Variables
Add below new user variable (or System variable) (To add new user variable click on New button under User variable for <USER>)

Click OK.
Add %SPARK_HOME%\bin to the path variable.
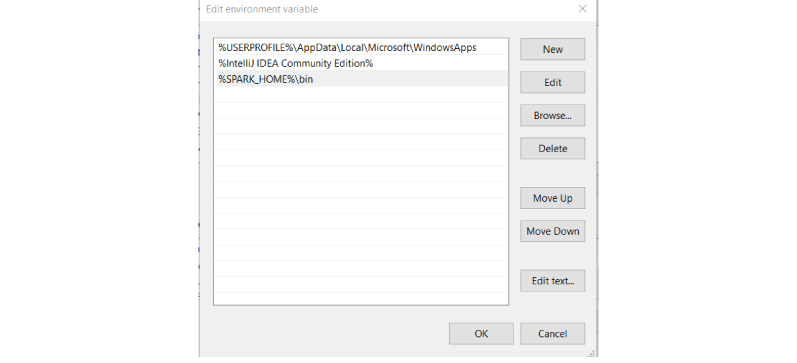
Click OK.
Step 6: Spark needs a piece of Hadoop to run. For Hadoop 2.7, you need to install winutils.exe.
You can find winutils.exe from below page
Download it.
Step 7: Create a folder called winutils in C drive and create a folder called bin inside. Then, move the downloaded winutils file to the bin folder.
C:\winutils\bin

Add the user (or system) variable %HADOOP_HOME% like SPARK_HOME.

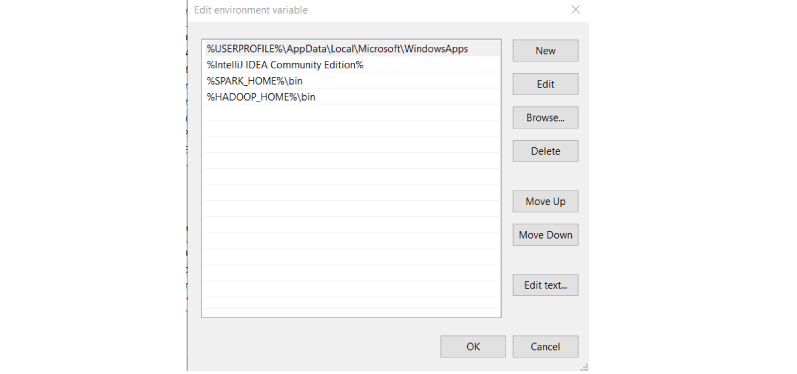
Click OK.
Step 8: To install Apache Spark, Java should be installed on your computer. If you don’t have java installed in your system. Please follow the below process
Java Installation Steps:
- Go to the official Java site mentioned below the page.
Accept Licence Agreement for Java SE Development Kit 8u201
- Download jdk-8u201-windows-x64.exe file
- Double Click on Downloaded .exe file, you will the window shown below.
- Click Next.
- Then below window will be displayed.
- Click Next.
- Below window will be displayed after some process.
- Click Close.
Test Java Installation:
Open Command Line and type java -version, then it should display installed version of Java

You should also check JAVA_HOME and path of %JAVA_HOME%\bin included in user variables (or system variables)
1. In the end, the environment variables have 3 new paths (if you need to add Java path, otherwise SPARK_HOME and HADOOP_HOME).

2. Create c:\tmp\hive directory. This step is not necessary for later versions of Spark. When you first start Spark, it creates the folder by itself. However, it is the best practice to create a folder.
C:\tmp\hive
Test Installation:
Open command line and type spark-shell, you get the result as below.
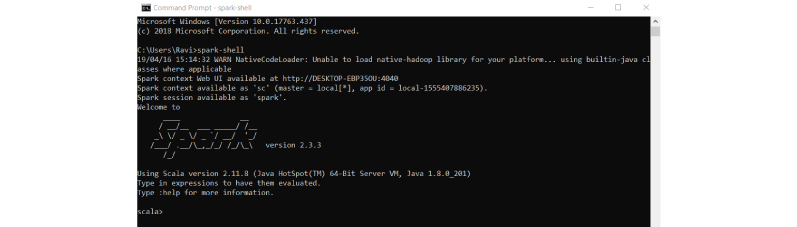
We have completed spark installation on Windows system. Let’s create RDD and Data frame
We create one RDD and Data frame then will end up.
1. We can create RDD in 3 ways, we will use one way to create RDD.
Define any list then parallelize it. It will create RDD. Below is code and copy paste it one by one on the command line.
val list = Array(1,2,3,4,5) val rdd = sc.parallelize(list)
Above will create RDD.
2. Now we will create a Data frame from RDD. Follow the below steps to create Dataframe.
import spark.implicits._
val df = rdd.toDF("id")Above code will create Dataframe with id as a column.
To display the data in Dataframe use below command.
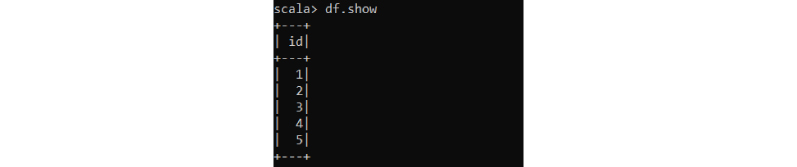
Df.show()
It will display the below output.
How to uninstall Spark from Windows 10 System:
Please follow below steps to uninstall spark on Windows 10.
- Remove below System/User variables from the system.
- SPARK_HOME
- HADOOP_HOME
To remove System/User variables please follow below steps:
Go to Control Panel -> System and Security -> System -> Advanced Settings -> Environment Variables, then find SPARK_HOME and HADOOP_HOME then select them, and press DELETE button.
Find Path variable Edit -> Select %SPARK_HOME%\bin -> Press DELETE Button
Select % HADOOP_HOME%\bin -> Press DELETE Button -> OK Button
Open Command Prompt the type spark-shell then enter, now we get an error. Now we can confirm that Spark is successfully uninstalled from the System.
Thanks to share good info about spark installation in windows.If you share in the form of youtube video its easy and convenient
ReplyDeleteRegards
Venu
spark training in Hyderabad
bigdata training in Hyderabad