The spark-submit command is a utility to run or submit a
Spark or PySpark application program (or job) to the cluster by
specifying options and configurations, the application you are
submitting can be written in Scala, Java, or Python (PySpark).
spark-submit command supports the following.You can run Spark applications locally or distributed across a cluster, either by using an interactive shell or by submitting an application. Running Spark applications interactively is commonly performed during the data-exploration phase and for ad hoc analysis. Spark Submit is a shell script to manage your spark application.
spark-submit --class org.apache.spark.examples.SparkPi \
--queue default \
--master yarn \
--deploy-mode cluster \
--driver-memory 4g \
--executor-memory 2g \
-- conf spark.executor.cores=4 \
--conf spark.dynamicAllocation.enabled=true
--conf spark.dynamicAllocation.maxExecutors=10
--conf spark.dynamicAllocation.enabled=true
--conf spark.executor.memory=10G
--conf spark.driver.memory=30G
--deploy-mode=cluster
--conf spark.dynamicAllocation.initialExecutors=2
--conf spark.dynamicAllocation.minExecutors=2
--conf spark.yarn.queue="root.ehub-xds_yarn"
--conf spark.broadcast.compress=true
--packages com.crealytics:spark-excel_2.11:0.13.0 --jars
lib/spark-examples*.jar \
100
You specify spark-submit with below options.
Class -- For Java and Scala applications, the fully qualified class name of the class containing the main method of the application.
conf -- Spark configuration property in key=value format. For values that contain spaces, surround "key=value" with quotes (as shown).
deploy-mode -- cluster and client.
driver-class-path -- Configuration and classpath entries to pass to the driver. JARs added with --jars are automatically included in the class path.
driver-cores -- Number of cores used by the driver in cluster mode.
Default: 1.
driver-memory -- Maximum heap size (represented as a JVM string; for example 1024m, 2g, and so on) to allocate to the driver. Alternatively, you can use the spark.driver.memory property.
files -- Comma-separated list of files to be placed in the working directory of each executor. For the client deployment mode, the path must point to a local file. For the cluster deployment mode, the path can be either a local file or a URL globally visible inside your cluster; see Advanced Dependency Management.
jars-- Additional JARs to be loaded in the classpath of drivers and executors in cluster mode or in the executor classpath in client mode. For the client deployment mode, the path must point to a local file. For the cluster deployment mode, the path can be either a local file or a URL globally visible inside your cluster; see Advanced Dependency Management.master -- The location to run the application.
packages -- Comma-separated list of Maven coordinates of JARs to include on the driver and executor classpaths. The local Maven, Maven central, and remote repositories specified in repositories are searched in that order. The format for the coordinates is groupId:artifactId:version.
py-files-- Comma-separated list of .zip, .egg, or .py files to place on PYTHONPATH. For the client deployment mode, the path must point to a local file. For the cluster deployment mode, the path can be either a local file or a URL globally visible inside your cluster; see Advanced Dependency Management.
repositories -- Comma-separated list of remote repositories to search for the Maven coordinates specified in packages.
Master Values Master
local- Run Spark locally with one worker thread (that is, no parallelism).
local[K] -- Run Spark locally with K worker threads. (Ideally, set this to the number of cores on your host.)
local[*]-- Run Spark locally with as many worker threads as logical cores on your host.
yarn Run using a YARN cluster manager. The cluster location is determined by HADOOP_CONF_DIR or YARN_CONF_DIR. See Configuring the Environment.
local- Run Spark locally with one worker thread (that is, no parallelism).
local[K] -- Run Spark locally with K worker threads. (Ideally, set this to the number of cores on your host.)
local[*]-- Run Spark locally with as many worker threads as logical cores on your host.
yarn Run using a YARN cluster manager. The cluster location is determined by HADOOP_CONF_DIR or YARN_CONF_DIR. See Configuring the Environment.
The
example above is the standard SparkPi example on YARN with one
important change; I modified the task count from 10 up to 100 in order
to have more monitoring data available for review. Deployment modes of spark, it specifies where the driver program will be run, basically, it is possible in two ways. At first, either on the worker node inside the cluster, which is also known as Spark cluster mode. Secondly, on an external client, what we call it as a client spark mode.
- Local Mode
- Client Mode
- Cluster Mode
What is dynamic memory allocation in spark?
Dynamic allocation allows Spark to, dynamically scale the cluster resources allocated for the Spark application.When dynamic allocation is enabled, if there are backlog of pending tasks for a Spark application, it can request for new executors.When the application becomes idle, its executors are released and the same can be acquired by other spark applications.
To enable Dynamic allocation for Spark, following steps could be used:
To enable Dynamic allocation for Spark, following steps could be used:
- spark.dynamicAllocation.enabled = true
- spark.shuffle.service.enabled = true
What is the number for executors to start with:
Initial number of executors (spark.dynamicAllocation.initialExecutors) to start with
- spark.dynamicAllocation.initialExecutors = 3 (Initial number of executors to run if dynamic allocation is enabled, this is same as "spark.dynamicAllocation.minExecutors")
Controlling the number of executors dynamically:
Then
based on load (tasks pending) how many executors to request. This would
eventually be the number what we give at spark-submit in static way. So
once the initial executor numbers are set, we go to min and max numbers.
- spark.dynamicAllocation.minExecutors = 3 (executors number will come to this number if executors are not in use, after 60 sec(default), controlled by "spark.dynamicAllocation. executorIdleTimeout")
- spark.dynamicAllocation.maxExecutors = 30 (maximum executors that job can request)
External Shuffle Service
First understand shuffle , it is a process of transferring a data from one machine to another machine.
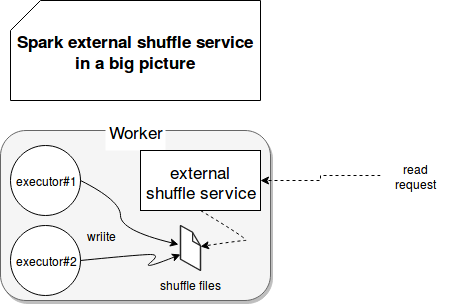
First understand shuffle , it is a process of transferring a data from one machine to another machine.
- If the executor processed the result and is idle for some time but because dynamic memory allocation executor will be released the result with executor will be lost so the other executor who is going to be read the data will not get the data so in this scenario shuffle process will fail. Whenever you are going for dynamic memory allocation it is mandatory enable the external shuffle service.
- External shuffle service is a distributed component of Apache Spark cluster responsible for the storage of shuffle blocks. When the Spark system runs applications that contain a shuffle process, an executor process also writes shuffle data and provides shuffle data for other executors in addition to running tasks.
- if you not define external shuffle service by default the executor will take care the shuffling the result. Let say executor -1 write the data to disk and executor -2 read the data from executor -1. Once you enable the external shuffle service shuffle service is done by External shuffle service and executor are free to shuffling the result even though executor is down External shuffle service will take care of the data .
When to ask new executors or give away current executors:
When do we request new executors (spark.dynamicAllocation.schedulerBacklogTimeout) – This means that there have been pending tasks for this much duration. So the request for the number of executors requested in each round increases exponentially from the previous round. For instance, an application will add 1 executor in the first round, and then 2, 4, 8 and so on executors in the subsequent rounds. At a specific point, the above property max comes into picture.
When do we give away an executor is set using spark.dynamicAllocation.executorIdleTimeout.
To conclude, if we need more control over the job execution time, monitor the job for unexpected data volume the static numbers would help. By moving to dynamic, the resources would be used at the background and the jobs involving unexpected volumes might affect other applications.
what is Kerberos ?
Kerberos is a secure authentication method developed by MIT that allows two services located in a non-secured network to authenticate themselves in a secure way. Kerberos, which is based on a ticketing system, serves as both Authentication Server and as Ticket Granting Server (TGS).
what is Kerberos ?
Kerberos is a secure authentication method developed by MIT that allows two services located in a non-secured network to authenticate themselves in a secure way. Kerberos, which is based on a ticketing system, serves as both Authentication Server and as Ticket Granting Server (TGS).
How to Kill the spark Job ?
yarn application -kill application_Id
Data Serialization
Serialization plays an important role in the performance of any distributed application. Formats that are slow to serialize objects into, or consume a large number of bytes, will greatly slow down the computation. Often, this will be the first thing you should tune to optimize a Spark application.
Java serialization: By default, Spark serializes objects using Java’s ObjectOutputStream framework, and can work with any class you create that implements java.io.Serializable. You can also control the performance of your serialization more closely by extending java.io.Externalizable. Java serialization is flexible but often quite slow, and leads to large serialized formats for many classes.
Kryo serialization: Spark can also use the Kryo library (version 4) to serialize objects more quickly. Kryo is significantly faster and more compact than Java serialization (often as much as 10x), but does not support all Serializable types and requires you to register the classes you’ll use in the program in advance for best performance.
You can switch to using Kryo by initializing your job with a SparkConf and calling conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").
This setting configures the serializer used for not only shuffling data between worker nodes but also when serializing RDDs to disk. The only reason Kryo is not the default is because of the custom registration requirement, but we recommend trying it in any network-intensive application. Since Spark 2.0.0, we internally use Kryo serializer when shuffling RDDs with simple types, arrays of simple types, or string type.
yarn application -kill application_Id
Data Serialization
Serialization plays an important role in the performance of any distributed application. Formats that are slow to serialize objects into, or consume a large number of bytes, will greatly slow down the computation. Often, this will be the first thing you should tune to optimize a Spark application.
Java serialization: By default, Spark serializes objects using Java’s ObjectOutputStream framework, and can work with any class you create that implements java.io.Serializable. You can also control the performance of your serialization more closely by extending java.io.Externalizable. Java serialization is flexible but often quite slow, and leads to large serialized formats for many classes.
Kryo serialization: Spark can also use the Kryo library (version 4) to serialize objects more quickly. Kryo is significantly faster and more compact than Java serialization (often as much as 10x), but does not support all Serializable types and requires you to register the classes you’ll use in the program in advance for best performance.
You can switch to using Kryo by initializing your job with a SparkConf and calling conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").
This setting configures the serializer used for not only shuffling data between worker nodes but also when serializing RDDs to disk. The only reason Kryo is not the default is because of the custom registration requirement, but we recommend trying it in any network-intensive application. Since Spark 2.0.0, we internally use Kryo serializer when shuffling RDDs with simple types, arrays of simple types, or string type.
Case 1 Hardware – 6 Nodes and each node have 16 cores, 64 GB RAM
First on each node, 1 core and 1 GB is needed for Operating System and Hadoop Daemons, so we have 15 cores, 63 GB RAM for each node
We start with how to choose number of cores:
Number of cores = Concurrent tasks an executor can run
So we might think, more concurrent tasks for each executor will give better performance. But research shows that any application with more than 5 concurrent tasks, would lead to a bad show. So the optimal value is 5. This number comes from the ability of an executor to run parallel tasks and not from how many cores a system has. So the number 5 stays same even if we have double (32) cores in the CPU
Number of executors:
Coming to the next step, with 5 as cores per executor, and 15 as total available cores in one node (CPU) – we come to 3 executors per node which is 15/5. We need to calculate the number of executors on each node and then get the total number for the job.
So with 6 nodes, and 3 executors per node – we get a total of 18 executors. Out of 18 we need 1 executor (java process) for Application Master in YARN. So final number is 17 executors.This 17 is the number we give to spark using –num-executors while running from spark-submit shell command
Memory for each executor:
From above step, we have 3 executors per node. And available RAM on each node is 63 GB
So memory for each executor in each node is 63/3 = 21GB.
However small overhead memory is also needed to determine the full memory request to YARN for each executor.
The formula for that overhead is max(384, .07 * spark.executor.memory)
Calculating that overhead: .07 * 21 (Here 21 is calculated as above 63/3) = 1.47
Since 1.47 GB > 384 MB, the overhead is 1.47
Take the above from each 21 above => 21 – 1.47 ~ 19 GB
So executor memory – 19 GB
Final numbers – Executors – 17, Cores 5, Executor Memory – 19 GB
Case 2 Hardware – 6 Nodes and Each node have 32 Cores, 64 GB
Number of cores of 5 is same for good concurrency as explained above.
Number of executors for each node = 32/5 ~ 6
So total executors = 6 * 6 Nodes = 36. Then final number is 36 – 1(for AM) = 35
Executor memory:
6 executors for each node. 63/6 ~ 10. Overhead is .07 * 10 = 700 MB. So rounding to 1GB as overhead, we get 10-1 = 9 GB
Final numbers – Executors – 35, Cores 5, Executor Memory – 9 GB
Case 3 – When more memory is not required for the executors
The above scenarios start with accepting number of cores as fixed and moving to the number of executors and memory.Now for the first case, if we think we do not need 19 GB, and just 10 GB is sufficient based on the data size and computations involved, then following are the numbers:
Cores: 5
Number of executors for each node = 3. Still 15/5 as calculated above.
At this stage, this would lead to 21 GB, and then 19 as per our first calculation. But since we thought 10 is ok (assume little overhead), then we cannot switch the number of executors per node to 6 (like 63/10). Because with 6 executors per node and 5 cores it comes down to 30 cores per node, when we only have 16 cores. So we also need to change number of cores for each executor.
So calculating again,
The magic number 5 comes to 3 (any number less than or equal to 5). So with 3 cores, and 15 available cores – we get 5 executors per node, 29 executors ( which is (5*6 -1)) and memory is 63/5 ~ 12.
Overhead is 12*.07=.84. So executor memory is 12 – 1 GB = 11 GB
Final Numbers are 29 executors, 3 cores, executor memory is 11 GB
No comments:
Post a Comment