Wide transformations are also called shuffle transformations as they may or may not depend on a shuffle.
GroupBy: Spark groupBy function is defined in RDD class of spark. It is a transformation operation which means it will follow lazy evaluation. This operation is a wide operation as data shuffling may happen across the partitions.
- In spark, groupBy is a transformation operation.Spark RDD groupBy function returns an RDD of grouped items.
- We need to pass one function (which defines a group for an element) which will be applied to the source RDD and will create a new RDD as with the individual groups and the list of items in that group.
- This operation will return the new RDD which basically is made up with a KEY (which is a group) and list of items of that group (in a form of Iterator).
- Order of element within the group may not same when you apply the same operation on the same RDD over and over.
- Additionally, this operation could be computationally costly when you are trying to perform some aggregation on grouped items.
val x = sc.parallelize(Array("Joseph","Jimmy","Tina","Thomas","James","Cory","Christine","Jackeline","Juan"), 3)
val y = x.groupBy(word => word.charAt(0))
y.collect
val y = x.groupBy(word => word.charAt(0))
y.collect

val x = sc.parallelize(Array("Joseph","Jimmy","Tina","Thomas","James","Cory","Christine","Jackeline","Juan"), 3)
val y = x.groupBy(_.charAt(0))
y.collect.foreach(println)
val y = x.groupBy(_.charAt(0))
y.collect.foreach(println)

you can see that RDD X contains different words with 3 partitions. It accepts a function word => word.charAt(0) which will get the first character of the word in upper case (which will be considered as a group). The output RDD Y which will contain the group(first character of the word) as a key and Iterator of all words belong to that group (all words starting from a character).
Important points
Important points
- groupBy is a transformation operation in Spark hence its evaluation is lazy
- It is a wide operation as it shuffles data from multiple partitions and create another RDD
- This operation is costly as it doesn’t us combiner local to a partition to reduce the data transfer
- Not recommended to use when you need to do further aggregation on grouped data
- groupBy(function)
- groupBy(function, [numPartition])
- groupBy(partitioner, function)
groupByKey()
When we use groupByKey() on a dataset it takes key-value pair (K, V) as an input produces RDD with key and list of values. As name suggest groupByKey function in Apache Spark just groups all values with respect to a single key. Unlike reduceByKey it doesn’t per form any operation on final output. It just group the data and returns in a form of an iterator. It is a transformation operation which means its evaluation is lazy.
Now because in source RDD multiple keys can be there in any partition, this function require to shuffle all data with of a same key to a single partition unless your source RDD is already partitioned by key. And this shuffling makes this transformation as a wider transformation.
Important points
- groupBy is a transformation operation in Spark hence its evaluation is lazy
- It is a wide operation as it shuffles data from multiple partitions and create another RDD
- This operation is costly as it doesn’t us combiner local to a partition to reduce the data transfer
- Not recommended to use when you need to do further aggregation on grouped data
val x = sc.parallelize(Array(("USA", 1), ("USA", 2), ("India", 1),("UK", 1), ("India", 4), ("India", 9),("USA", 8), ("USA", 3), ("India", 4), ("UK", 6), ("UK", 9), ("UK", 5)), 3)
val y = x.groupByKey
y.getNumPartitions
val y = x.groupByKey(2) --Define partition
y.getNumPartitions
y.collect
val data = sc.parallelize(Array(('k',5),('s',3),('s',4),('p',7),('p',5),('t',8),('k',6)),3)
val group = data.groupByKey().collect()
group.foreach(println)
val y = x.groupByKey
y.getNumPartitions
val y = x.groupByKey(2) --Define partition
y.getNumPartitions
y.collect
val data = sc.parallelize(Array(('k',5),('s',3),('s',4),('p',7),('p',5),('t',8),('k',6)),3)
val group = data.groupByKey().collect()
group.foreach(println)
Avoid Group By
Let's look at two different ways to compute word counts, one using reduceByKey and the other using groupByKey:
val words = Array("one", "two", "two", "three", "three", "three")
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
val wordCountsWithReduce = wordPairsRDD.reduceByKey(_ + _).collect()
val wordCountsWithGroup = wordPairsRDD.groupByKey().map(t => (t._1, t._2.sum)).collect()
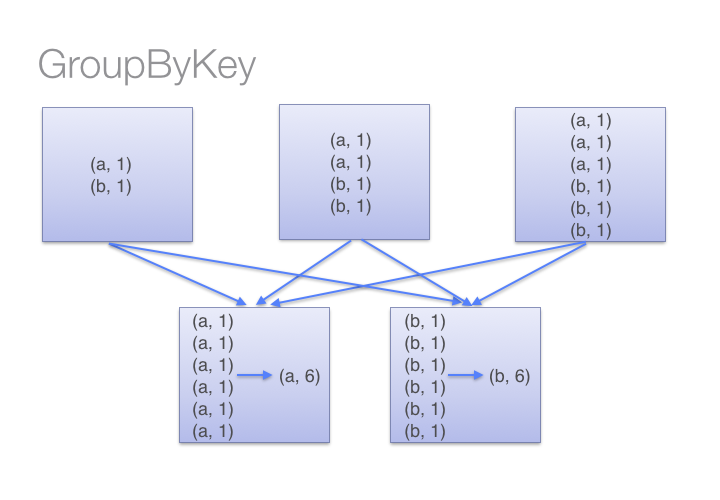
While both of these functions will produce the correct answer, the reduceByKey example works much better on a large dataset. That's because Spark knows it can combine output with a common key on each partition before shuffling the data.
Look at the diagram below to understand what happens with reduceByKey. Notice how pairs on the same machine with the same key are combined (by using the lamdba function passed into reduceByKey) before the data is shuffled. Then the lamdba function is called again to reduce all the values from each partition to produce one final result.
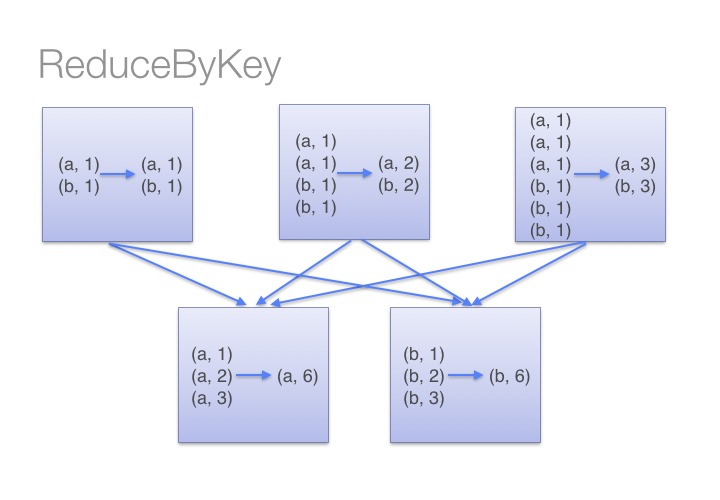
On the other hand, when calling groupByKey - all the key-value pairs are shuffled around. This is a lot of un-nessary data to being transferred over the network.
To determine which machine to shuffle a pair to, Spark calls a partitioning function on the key of the pair. Spark spills data to disk when there is more data shuffled onto a single executor machine than can fit in memory. However, it flushes out the data to disk one key at a time - so if a single key has more key-value pairs than can fit in memory, an out of memory exception occurs. This will be more gracefully handled in a later release of Spark so the job can still proceed, but should still be avoided - when Spark needs to spill to disk, performance is severely impacted.
ReduceByKey(func, [numTasks])
combineByKey
("A", 3), ("A", 9), ("A", 12),("B", 4), ("B", 10), ("B", 11)
Partition 1
A=3 --> createCombiner(3) ==> accum[A] = (3, 1)
A=9 --> mergeValue(accum[A], 9) ==> accum[A] = (3 + 9, 1 + 1)
B=11 --> createCombiner(11) ==> accum[B] = (11, 1)
Partition 2
A=12 --> createCombiner(12) ==> accum[A] = (12, 1)
B=4 --> createCombiner(4) ==> accum[B] = (4, 1)
B=10 --> mergeValue(accum[B], 10) ==> accum[B] = (4 + 10, 1 + 1)
Merge partitions together
A ==> mergeCombiner((12, 2), (12, 1)) ==> (12 + 12, 2 + 1)
B ==> mergeCombiner((11, 1), (14, 2)) ==> (11 + 14, 1 + 2)
So, you should get back an array something like this:
Array((A, (24, 3)), (B, (25, 3)))
sortByKey
When we apply the sortByKey() function on a dataset of (K, V) pairs, the data is sorted according to the key K in ascending or descending order as specified in the boolean value.
In
spark, when called on a DStream of (K, V) pairs, reduceByKey(func)
return a new DStream of (K, V) pairs. However, it happens when key
values are aggregated by using the given reduce function. ReduceByKey
combining all the values with another value with the exact same
type.Data is combined at each partition , only one output for one key at
each partition to send over network.
val words = line.flatMap(_.split(" "))
val pair = words.map(word => (word, 1))
val wordCount = pair.reduceByKey(_ + _)
wordCount.print()
val words = Array("one","two","two","four","five","six","six","eight","nine","ten")
val data = sc.parallelize(words).map(w => (w,1)).reduceByKey(_+_)
data.foreach(println)combineByKey
- createCombiner: This function is invoked only once for every key.It creates the initial value of the accumulator
- mergeValue: This function is called to add the new value to the existing accumulator of that key(which was created by createCombiner)
- mergeCombiners: This Function is called to combine values of a key across multiple partitions
("A", 3), ("A", 9), ("A", 12),("B", 4), ("B", 10), ("B", 11)
Partition 1
A=3 --> createCombiner(3) ==> accum[A] = (3, 1)
A=9 --> mergeValue(accum[A], 9) ==> accum[A] = (3 + 9, 1 + 1)
B=11 --> createCombiner(11) ==> accum[B] = (11, 1)
Partition 2
A=12 --> createCombiner(12) ==> accum[A] = (12, 1)
B=4 --> createCombiner(4) ==> accum[B] = (4, 1)
B=10 --> mergeValue(accum[B], 10) ==> accum[B] = (4 + 10, 1 + 1)
Merge partitions together
A ==> mergeCombiner((12, 2), (12, 1)) ==> (12 + 12, 2 + 1)
B ==> mergeCombiner((11, 1), (14, 2)) ==> (11 + 14, 1 + 2)
So, you should get back an array something like this:
Array((A, (24, 3)), (B, (25, 3)))
sortByKey
When we apply the sortByKey() function on a dataset of (K, V) pairs, the data is sorted according to the key K in ascending or descending order as specified in the boolean value.
val rdd=sc.parallelize(Seq(("maths",52),("english",75),("science",82), ("computer",65), ("maths",85)))
val rdd1 = rdd.sortByKey().collect -- by default Ascending
rdd1.foreach(println)
val sorted = rdd1.sortByKey(false).collect
val sorted = rdd1.sortByKey(false).collect
rdd.flatMap(x => x.split(" ")).distinct.map(y => (y,1)).sortByKey() -- by default Ascending
.collect
rdd
.flatMap(words => words.split(" "))
.distinct
.map(x => (x,1))
.sortByKey(false) -- Ascending order (false)
.collect
res37: Array[(String, Int)] = Array((Spark,1), (Hello,1), (Dataneb,1), (Apache,1))
CountByValue():- In spark, when called on a DStream of elements of type K, countByValue() returns a new DStream of (K, Long) pairs. Only where the value of each key is its frequency in each spark RDD of the source DStream.
val word = lines.flatMap(_.split(" "))
word.countByValue().print()
Join:- It takes datasets of type key-value pair and works same like sql joins. For no match value will be None. For example,
val rdd1 = sc.parallelize(List("Apple","Orange", "Banana", "Grapes", "Strawberry", "Papaya")).map(words => (words,1))
val rdd2 = sc.parallelize(List("Apple", "Grapes", "Peach", "Fruits")).map(words => (words,1))
repartation()-
rdd1.join(rdd2).collect
rdd1.rightOuterJoin(rdd2).collect
rdd1.leftOuterJoin(rdd2).collect
rdd1.fullOuterJoin(rdd2).collect
cartesian:- Same like cartesian product, return all possible pairs of elements of dataset.
scala> val rdd1 = sc.parallelize(List("Apple","Orange", "Banana", "Grapes", "Strawberry", "Papaya"))
rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[111] at parallelize at <console>:24
scala> val rdd2 = sc.parallelize(List("Apple", "Grapes", "Peach", "Fruits"))
rdd2: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[112] at parallelize at <console>:24
scala> rdd1.cartesian(rdd2).collect
res46: Array[(String, String)] = Array((Apple,Apple), (Apple,Grapes), (Apple,Peach), (Apple,Fruits), (Orange,Apple), (Banana,Apple), (Orange,Grapes), (Banana,Grapes), (Orange,Peach), (Banana,Peach), (Orange,Fruits), (Banana,Fruits), (Grapes,Apple), (Grapes,Grapes), (Grapes,Peach), (Grapes,Fruits), (Strawberry,Apple), (Papaya,Apple), (Strawberry,Grapes), (Papaya,Grapes), (Strawberry,Peach), (Papaya,Peach), (Strawberry,Fruits), (Papaya,Fruits))
coalesce()- coalesce and repartition both shuffles the data to increase or decrease the partition, but repartition is more costlier operation as it re-shuffles all data and creates new partition. For example,
scala> val distData = sc.parallelize(1 to 16, 4)
distData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[128] at parallelize at <console>:24
// current partition size
scala> distData.partitions.size
res63: Int = 4
// checking data across each partition
scala> distData.mapPartitionsWithIndex((index, iter) => if (index == 0) iter else Iterator()).collect
res64: Array[Int] = Array(1, 2, 3, 4)
scala> distData.mapPartitionsWithIndex((index, iter) => if (index == 1) iter else Iterator()).collect
res65: Array[Int] = Array(5, 6, 7, 8)
scala> distData.mapPartitionsWithIndex((index, iter) => if (index == 2) iter else Iterator()).collect
res66: Array[Int] = Array(9, 10, 11, 12)
scala> distData.mapPartitionsWithIndex((index, iter) => if (index == 3) iter else Iterator()).collect
res67: Array[Int] = Array(13, 14, 15, 16)
// decreasing partitions to 2
scala> val coalData = distData.coalesce(2)
coalData: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[133] at coalesce at <console>:25
// see how shuffling occurred. Instead of moving all data it just moved 2 partitions.
scala> coalData.mapPartitionsWithIndex((index, iter) => if (index == 0) iter else Iterator()).collect
res68: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8)
scala> coalData.mapPartitionsWithIndex((index, iter) => if (index == 1) iter else Iterator()).collect
res69: Array[Int] = Array(9, 10, 11, 12, 13, 14, 15, 16)
repartation()-
Notice how it re-shuffled everything to create new partitions as compared to previous RDDs - distData and coalData. Hence repartition is more costlier operation as compared to coalesce.
scala> val repartData = distData.repartition(2)
repartData: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[139] at repartition at <console>:25
// checking data across each partition
scala> repartData.mapPartitionsWithIndex((index, iter) => if (index == 0) iter else Iterator()).collect
res70: Array[Int] = Array(1, 3, 6, 8, 9, 11, 13, 15)
scala> repartData.mapPartitionsWithIndex((index, iter) => if (index == 1) iter else Iterator()).collect
res71: Array[Int] = Array(2, 4, 5, 7, 10, 12, 14, 16)
Points to Note
- reduce() is similar to fold() except reduce takes a ‘Zero value‘ as an initial value for each partition.
- reduce() is similar to aggregate() with a difference; reduce return type should be the same as this RDD element type whereas aggregation can return any type.
- reduce() also same as reduceByKey() except reduceByKey() operates on Pair RDD
Distinct
Return a new RDD that contains the distinct elements of the source RDD.
val rdd = sc.parallelize(List((1,20), (1,21), (1,20), (2,20), (2,22), (2,20), (3,21), (3,22)))
rdd.distinct.collect().foreach(println)
Return a new RDD that contains the distinct elements of the source RDD.
val rdd = sc.parallelize(List((1,20), (1,21), (1,20), (2,20), (2,22), (2,20), (3,21), (3,22)))
rdd.distinct.collect().foreach(println)
No comments:
Post a Comment